Deep Learning with TensorFlowOnSpark
TensorFlowOnSpark provides a framework for running TensorFlow on Apache Spark. It allows distributed training and inference on Apache Spark clusters. It requires minimal changes to existing TensorFlow programs. See. [https://github.com/yahoo/TensorFlowOnSpark/wiki/Conversion-Guide] for more information on TensorFlow to TensorFlowOnSpark conversion.
Setting Up and Running TensorFlowOnSpark
Prerequisites
Follow the instruction in Launch a Spark Cluster to lauch a Spark cluster on Kitwai system.
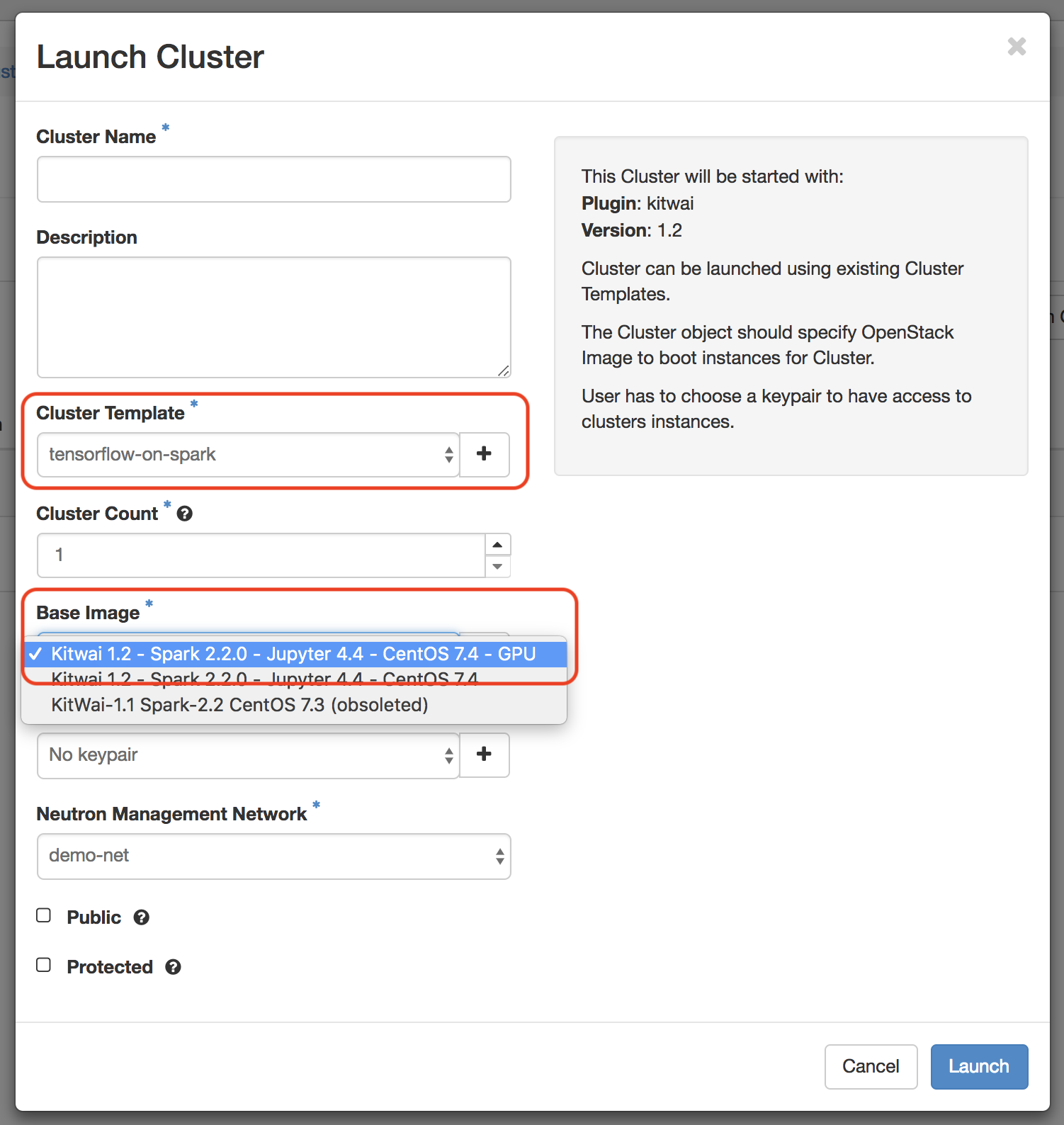
To lauch GPU cluster, select tensorflow-on-spark as cluster template and Kitwai 1.2 - Spark 2.2.0 - Jupyter 4.4 - CentOS 7.4 - GPU as base image as shown here.
Installing TensorFlowOnSpark
Install TensorFlow by invoking following commands based on the machine setting (with or without GPUs support). This must be done on every nodes in the Spark clusters.
TensorFlow
sudo pip install tensorflow
TensorFlow with GPU support
sudo pip install tensorflow-gpu
For low-memory machine, uses --no-cache-dir option when installing to avoid memory error during installation.
TensorFlow with GPU support requires NVIDIA CUDA Deep Neural Network library (cuDNN), which can be download from here
Next step is to install TensorFlowOnSpark by using following command.
sudo pip install tensorflowonspark
The last step is to upgrade TensorFlow and TensorFlowOnSpark to the latest version by using following commands.
TensorFlow
sudo pip install -U tensorflow
sudo pip install -U tensorflowonspark
TensorFlow with GPU support
sudo pip install -U tensorflow-gpu
sudo pip install -U tensorflowonspark
Environment Variables
Following variables must be set before running TensorFlowOnSpark programs.
JAVA_HOME: The location of Java installationHADOOP_HDFS_HOME: The location of HDFS installationLD_LIBRARY_PATH: To include the path tolibjvm.soandlibhdfs.soCLASSPATH: Add Hadoop jars to class path. Fromlibhdfsdocumentation,CLASSPATHmust set to$($HADOOP_HDFS_HOME/bin/hadoop classpath --glob)
Running TensorFlowOnSpark Programs
Following is an example running script for TensorFlowOnSpark programs.
spark-submit \
--master spark://localhost:7077 \
--conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \
--conf spark.executorEnv.HADOOP_HDFS_HOME="$HADOOP_HOME" \
--conf spark.executorEnv.LD_LIBRARY_PATH="$JAVA_HOME/lib/amd64/server:$HADOOP_HOME/lib/native" \
--conf spark.executorEnv.CLASSPATH=$($HADOOP_HDFS_HOME/bin/hadoop classpath --glob) \
mnist_data_setup.py \
--output examples/mnist/csv \
--format csv
TensorFlowOnSpark programs are launched on the cluster through spark-submit command. The --master flag indicates the target Spark cluster. The address of the target cluster is specified using spark://<addr>:<port> format, where addr is the address of the master instance and port is the port that the master is listened to. In the example, a program is submitted to the master hosted in the local machine and listened to port 7077.
Users can set environment variables through --conf spark.executorEnv.<name>, where <name> is an environment variable name. The main program, e.g. mnist_data_setup.py in the example, and its parameters are placed at the end of the submission command.
For a program that is spread across multiple python scripts, --py-files can be used to specify other python scripts used in the program execution. Multiple python files can be specified together by separating each file using commas. For example,
--py-files first.py,second.py
Multiple python scripts can also be compressed in a zip file and used in the same manner. For example,
--py-files first.zip,second.py,third.zip
TensorFlowOnSpark has support for accessing data inside HDFS. Only file paths to read and write data need to be changed to HDFS paths, e.g. hdfs://namenode:8020/path/to/file.ext.
Troubleshooting
Error Error executing Jupyter command : [Errno 2] No such file or directory when running spark-submit
This is caused by Jupyter, which can be solved by unsetting following environment variables
unset PYSPARK_DRIVER_PYTHON
unset PYSPARK_DRIVER_PYTHON_OPTS